

Sayandeep Dey
he/him | age 16 | Calgary, AB
CYSF Gold Medalist | C.K. & Conchita Hao Award - Intermediate (CYSF) | CWSF participant
Edited by Michel Hijazin
INTRODUCTION
The use of plastics is viewed as a necessity of human life in the modern age. Plastics are present in almost every aspect of the modern age and more than 380 million tons (The Facts, 2022) of plastic are produced and consumed globally every year. In the last few decades, plastic production has outplaced plastic recycling significantly and most of the plastics end up in the environment rather than landfills. Since almost all plastics are non-biodegradable, they remain in the environment whether that be in the ocean, or scattered around land, or even dispersed into the air. For example, under certain conditions large plastics turn into minuscule forms called microplastics (Microplastics, 2021), which are so light that they can flow along fluids and into the respiratory systems of animals, severely affecting any who inhale them. Plastic pollution is all around the biosphere, and it is one of the most prominent types of pollution there is.

Figure 1: Key figures on current plastics environment (Plastic waste and pollution reduction, 2022)
One thing that the global community needs to do is limit the production of new plastics while still meeting the demand. Recycling waste plastics offers a viable solution to plastic pollution. However, the plastic recycling process is complex and inefficient. One of the major bottlenecks in the recycling process is the inefficient sorting and segregation of waste plastics. The lack of technological advancement in the sorting of waste plastics batch results in considerable contamination of the batch which often becomes unappealing to recycling industries. There are thousands of different varieties of plastic available courtesy to different types of resin and combination of various additives to the basic resin. The fluctuating material quality and lack of infrastructure and recycling mechanism makes the recycling process sloppy. Currently, the rate of recycling is limited to less than 10% (Plastic waste and pollution reduction, 2022) of the plastic produced.
To make waste plastics from postconsumer recyclable, it is necessary to sort waste not only into fractions such as metal, paper, or glass but also into various type of plastics. It is also important to distinguish and sort to various plastics material by their types. To facilitate the recycling, worldwide labelling of seven types of plastics based on resin identification code (RIC) was introduced. But after postconsumer, the waste plastics come in a mixed batch which often become challenging to sort by manual methods. The current sorting method is heavily dependent on manual sorting which often leads to significant errors and poses major limitation of extensive sorting. One option is the use of computer image recognition techniques in combination with artificial intelligence.



Figure 2 (from left to right): 2a - Household used plastics to go to recycling centre; 2b - Manual inadequate sorting of plostics at bottle depot; 2c - Contaminated waste plastics go to final recycling centre.
The project seeks to improve the sorting efficiency of a primary base facility like city’s Bottle Depot where most of the recyclable household plastics are segregated manually into limited categories. The method can then be extended to other downstream recycling facilities to achieve greater quality of final recycle plastic by avoiding contamination.
Hypothesis
ML and IP technology may dramatically improve waste plastics sorting accuracy, eliminate contamination issues, increase sorting speed and moreover, the recycling facilities can accomplish extensive sorting. Overall, this would increase the waste plastics recycling rate.
Keywords: Plastic Recycling, Machine Learning, Image Processing, Resin Code (RIC), Waste Plastics, Contamination, Plastic Recycling Rate.
PROCEDURE METHODOLOGY
Image Processing and Machine Learning
Artificial intelligence (AI) technique known as "deep learning" enables machines to mimic human learning (Burns, Bush, 2021). When identifying different materials, humans draw connections between what they have previously seen and what they are currently viewing. Similar tasks are taught to machines, but considerably quicker. It picks up data from tens of thousands of recorded photos of particular material categories that need to be divided throughout the sorting process. Deep learning uses simulation to learn complicated tasks by simulating the action of many layers of neurons in the human brain. In this manner, the system learns how to link the synthetic neurons during machine learning to categorise things.
Image Processing is a technique for applying operations on an image to extract relevant information from it. It is a form of signal processing where a picture serves as the input and either the image or its traits/features serve as the output. The three main steps towards image processing are:
Importing Image
Analyzing and manipulating the image
Output based on image analysis
This program was made in Google Colaboratory, a free platform where one can execute Python without any required configurations. This study uses a deep learning algorithm to train images to recognize plastics and the model follows the following sequence (Figure 3).

Figure 3: Model Development Process
Data Collection
It was imperative to find a dataset of images that contained a broad range of the different types of materials present in those batches. An open-sourced dataset (ARKADIY SEREZHKIN, 2020) which contained a set of 5000 images, categorized into four different categories: milk cartons, aluminum cans, glass bottles and plastic bottles was used to build the model.
Data Processing
After obtaining the dataset, the next step is creating variables and directories for the algorithm to use. The images in the dataset were then assigned to two different directories that were created. One directory was called: ‘training_data’, which is the images to be used to train the model. All 5000 images of the dataset were assigned to this directory. Another directory called: ‘validation_data’ was created. This directory includes 20% of the images from the original dataset at random. This is used to broadly test the model’s accuracy and see if the model is functioning after training. Since the model cannot comprehend images at a different pixel size, all the images in both directories were resized to be 64x64 pixel images. This was done using a single resizing command.
Machine Learning
After assigning all the variables and directories, the next step is to build the model. This model is a custom built Convolutional Neural Network (CNN) based model, which is a mathematical model of an artificial neural network. The structure of neurons is created similarly to the structure of the mammalian visual cortex. The local pixel arrangement determines the shape of the object. CNN first recognizes smaller local patterns in the image and then combines them into more complicated shapes. Convolutional Neural Networks may be an adequate solution to the problem of sorting waste because they are very effective in recognizing objects in the image. In this model, there are 2 convolutional layers, 2 pooling layers, and a fully connected layer. The neural network has 4 layers, the first compromising of 500 neurons, then 250 neurons, 100 neurons, and the last layer having only 4 neurons. Both convolutional layers use Conv2D which is a tool in CNN that contains most of the computation in the neural network. This part of CNN deciphers the image and converts the image to basic numbers that a computer can understand. The Pooling layer uses MaxPooling which is a tool in CNN that resizes, recolors, and shortens the image to a 1-line array so the computer can identify and recognize the image. The final layer is the fully connected layer, which is a full neural network that connects the pooling layers with the convolutional layers. Since there are 2 pooling layers and 2 convolutional layers, the neural network has 4 layers, each composed of a different number of neurons mentioned above.

Figure 4: CNN Process
Activation Keys
Another feature present in the model were the activation functions. Activation functions control and regulate the output of all the neurons in a ML program. What is meant by this is that the activation functions control the inputs and outputs for all the nodes present for a model. In figure 4, the image below the ‘Fully Connected’ Label is a classic neural network, comprised of little circles, which are the nodes, and lines connecting a circle to every other circle. There are 3 layers to this neural network, and a line connecting one node to all the other nodes in the next layer as shown in the figure. These nodes essentially transmit information from one layer to another, and an activation function is regulating the information a node receives and sends. For each layer of the model, the activation key ‘ReLu’ was used. For the last layer of the model however, the activation key used was softmax. ReLu is common within layers of the neural network as it regulates the information, which is passed from each node accordingly, and does not let it fall below a certain level, and softmax is used for multiclass issues. Because a computer based neural network can’t read images like human brains can, computers analyze images as numbers as mentioned in the previous paragraph. What each of the neurons do, is take a percentage of that number which is inputted into it and output that new percent. What these activation keys do is allow that data to be sent to other neurons. Now if a neuron miscalculates and has a value which it is not supposed to have, then the activation key will prevent that neuron from messing up the entire neural network, acting like a safeguard for the neural network. What softmax is essentially doing is regulating the final layer of the neural network, as it is split up into several different neurons, with all varying percentages as shown in the last layer of the neural network in Figure 4.
Compilation
Compilation is the final step towards tweaking the model before it is ready to be trained. The model compilation consists of three sections: loss, metrics, and optimizer. The loss was measured in ‘categorical_crossentropy’, a loss function used to compute the loss between the labels and predictions. This is just to calculate the number of times the model incorrectly labeled a picture and show it as a percentage after training. The accuracy of the model was also measured after training and was shown as a percentage. Finally, the optimizer ‘adam’ was used to optimize the inputs that the neurons had in the neural network and optimize the accuracy of the model as much as it could.
Training Process
The last part of the model development is to train the model. The model ran through 50 epochs of the ‘training_data’ directory, and each epoch took about 50 seconds to complete. An epoch is how many times the model goes through all the images in the dataset. The total time of training was about one hour, which can be improved easily with better computer hardware. It is important to note that this is not the prediction time, but the time taken to fully train the model.
MODEL DEMONSTRATION & RESULTS
To be fully certain that the model was accurate and functioning correctly, the predictions were tested with real picture of waste plastics. The other purpose of this demonstration was to evaluate the model accuracy, as well as the speed of detection.
The model’s accuracy is defined as how much of the dataset it can correctly memorize and categorize. The model's accuracy was calculated to be 98%, which means that out of all the photos in the dataset, the model can successfully identify 98% of them. It's vital to remember that the model accuracy does not correspond to the real accuracy of image prediction. The photos in the utilised open-sourced dataset (5) were of poor quality and had unsuitable backgrounds. The model has a very difficult time identifying patterns and other things in photos. If this technique were to be used by a company, a better, more reliable, and larger dataset containing distinct images would be required (preferably with a black background). The following graphs show how well my model predicts images from the data every epoch.

Figure 5: Model Accuracy per Epoch
TRAINING & VALIDATION
The research consisted in training the prepared networks and determining the classification accuracy using different divisions of the input data into training and validation data. Meaning that this model was run multiple times with different ratios of validation and training data (first test contained 90% training data, and 10% validation data, second test contained 80% training data, and 20% validation data, etc).
The network learning process was conducted with sets of data described above. The training also consisted of various sizes of images, till the perfect resolution was found. The factors that were taken into account for each resolution type were how accurately the model performed and how long the model took to train. Images were first resized to 4x4 pixel images, then 16x16, then 32x32, 64x64, 128x128 all the way up to 512x512. Another thing that was altered was how many epochs were used to train the model. An epoch is however many times the model iterates through all the images we provide it.
Analyzing the results of experiments in the case of our 4-layer network and images 64x64, 100 epochs are enough to obtain a tolerable level. Further training, also with a lower learning rate, does not give significant effects of accuracy. Achieved accuracy of 98% after 100 epochs is a good result. The results of the experiments showed that 80% training data and 20% validation data were the most accurate out of all the different permutations. For the image resolution, the experiments showed that as the resolution was increased so did the model accuracy, however, the time it took to train the model significantly increased as well, so it was deemed inefficient. 64x64 images were the optimal choice with good model accuracy and low training times. 100 epochs were the perfect number of epochs the model needed, and any more or any less resulted in a decrease in accuracy.
A variety of unique waste plastic photos were fed into the algorithm and the predictions were recorded to show the model. The likelihood that the model will properly identify an image input serves as the basis for determining the image prediction accuracy. This ended up being 95% correct on average, meaning that the model was able to accurately predict 95% of the custom photos that were used to test it, including low-quality photographs. The outcomes of the model predictions for a few photographs that were examined are shown in the following table (Figure 6).

Figure 6: Model Predictions on random images
The speed of the model is defined as the time taken by the model to predict the image and categorize it into a certain type. The speed is dependent on complexities within the picture like the background or image quality. One way to increase the speed is to lower the image resolution of the images the model was trained with however this results in a loss of accuracy.

Figure 7: Model speed
DISCUSSION
The margin of recycling waste plastics mechanically or chemically is huge. But each recycling process requires high purity of sorting to avoid contamination. When separating these plastics, cross contamination might occur if the appropriate sorting process is not adapted. For example, PVC type plastic material (RIC 3) must not be contaminated with PET (RIC 1) to recycle. The recycling facility could be converted into a completely automated system, eliminating the current practice of manual sorting process to achieve highest purity.
The system with a computer dedicated to image processing may be used to identify the type of plastic from which the waste is made. The system will use a camera and a computer with computer vision software to classify plastic garbage. The classifier in form of a program controls the output in some form like air force through an air suppled air nozzle to manage the waste to the right container. The algorithm in the system uses image processing techniques for image preprocessing. The following schematic represents the proposed system.

Figure 8: Upgraded Plastic Recycling Process
An extensive sorting from a batch of household waste is possible with an AI-assisted automated sorting system in a base facility like Bottle Depot. The following sorting objective can be met.
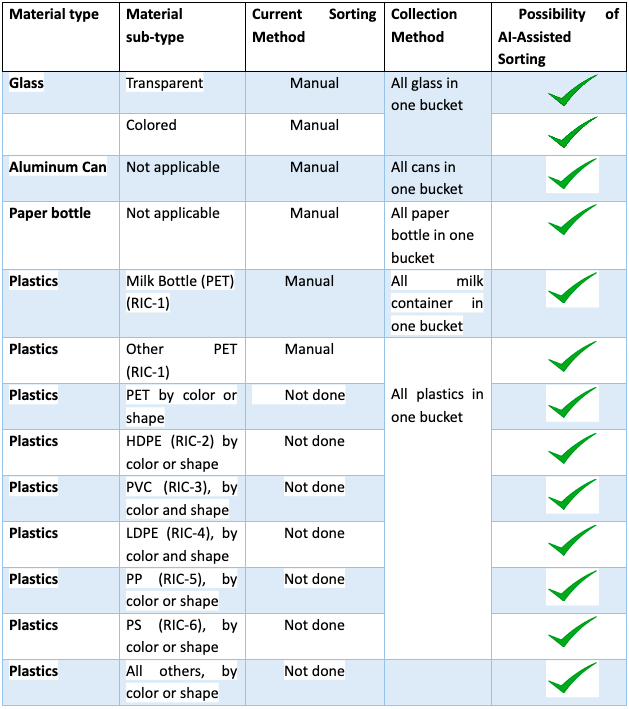
Table 1: Applications of AI assisted technology in Waste Plastic Sorting Process
CONCLUSION
In conclusion, the pictographic evaluation and categorization of the items from the waste plastic batch produce desirable results. Combining the advances in ML with IP supported by computer-built algorithms and other devices like cameras, sensors etc. to derive the desired output will make the sorting process highly efficient in terms of classifying and sorting items which would help extensive sorting from a heavily contaminated plastic batch. The result of high purity product from an upstream sorting process makes the downstream process more effective making room to recycle more material. Ultimately, the improvement would result in fewer plastics going to landfills or leaking into the environment. More recycling of waste plastics leads to a reduction of reliance on fossil feeds for plastic production, leading to overall lower GHG emissions. The other benefits can be viewed as:
The automated computerized sorting system will generate online inventory data which will be very helpful for the logistics purposes.
Because of the production of the high purity plastics, instead of mixed plastics, the base facility can obtain additional premiums to compensate their for capital investment.
The sorting process can be at a much faster rate.
The hands-free sorting system will avoid any errors to occur.
The facility can be run 24X7 to obtain and process materials
While the sorting of components like glass material, aluminum can, paper bottle, major verities of plastics etc. can be accomplished at very high accuracy by IP/ML, the segregation of plastic of similar types or heavily distorted type may be difficult to be predicted by IP/ML. However, there are some ways we can try to eliminate these subtleties. For example, an embedded unique identifier in each plastic product that can be recognized by cameras on the sorting line may be helpful to tackle the dirty or heavily distorted plastics. The open-sourced dataset that was used had poor quality images and was extremely hard for the model to decipher patterns within images. If this system were adopted for an industry, a much better, robust, and larger dataset would be needed. With all of these in mind however, the current recycling process can be greatly boosted with this ML and IP system that this project proposes. This project only demonstrated a small fraction of the power ML and IP technology can have in the plastic recycling industry and the various benefits it can bring, and to bring it to fruition will require a more extensive system which follows the basic system provided in this project. With all this in mind, this experiment has proved that the plastic recycling process can be greatly benefitted with the introduction of ML and IP technologies.
REFERENCES
Arkadiy Serezhkin. (2020). Drinking Waste Classification. Retrieved from Kaggle: https://www.kaggle.com/datasets/arkadiyhacks/drinking-waste-classification
Microplastics. (2021, 05 04). Retrieved from NATURE: https://www.nature.com/articles/d41586-021-01143-3
Plastic waste and pollution reduction. (2022). Retrieved from Canada.ca: https://www.canada.ca/en/environment-climate-change/services/managing-reducing-waste/reduce-plastic-waste
The Facts. (2022). Retrieved from Plasticoceans: https://plasticoceans.org/the-facts/
Burns, E., and Brush, K. (2021, Marth 29). What is deep learning and how does it work. SearchEnterpriseAI. Retrieved July 18, 2022, from https://www.techtarget.com/searchenterpriseai/definition/deep-learning-deep-neural-network#:~:text=Deep%20learning%20is%20a%20type,includes%20statistics%20and%20predictive%20modeling.
Aig, A. E., Aigiomawu Ehiaghe Computer Vision | Software Developer | Technical Writer, Ehiaghe, A., & Computer Vision | Software Developer | Technical Writer. (2021, November 15). What image processing techniques are actually used in the ML industry? neptune.ai. Retrieved April 27, 2022, from https://neptune.ai/blog/what-image-processing-techniques-are-actually-used-in-the-ml-industry
Anbarjafari, G. (n.d.). 1. introduction to image processing. Sisu@UT. Retrieved April 27, 2022, from https://sisu.ut.ee/imageprocessing/book/1
Anbarjafari, G. (n.d.). 2. sampling and quantization. Sisu@UT. Retrieved April 27, 2022, from https://sisu.ut.ee/imageprocessing/book/2
Brownlee, J. (2020, May 27). How to use the keras functional API for Deep Learning. Machine Learning Mastery. Retrieved April 27, 2022, from https://machinelearningmastery.com/keras-functional-api-deep-learning/
Brownlee, J. (2021, January 21). How to choose an activation function for deep learning. Machine Learning Mastery. Retrieved April 27, 2022, from https://machinelearningmastery.com/choose-an-activation-function-for-deep-learning/#:~:text=An%20activation%20function%20in%20a,a%20layer%20of%20the%20network.
CSCE883 machine learning | main ... - mleg.cse.sc.edu. (n.d.). Retrieved April 28, 2022, from http://mleg.cse.sc.edu/edu/csce883/index.php?n=Main
Deep learning as compute paradigm - iro.umontreal.ca. (n.d.). Retrieved April 28, 2022, from https://www.iro.umontreal.ca/~memisevr/talks/memisevicDLsummit2016.pdf
Easiest way to download kaggle data in Google Colab: Data Science and Machine Learning. Kaggle. (n.d.). Retrieved April 27, 2022, from https://www.kaggle.com/general/74235
Google. (n.d.). Descending into ML: Training and loss | machine learning crash course | google developers. Google. Retrieved April 27, 2022, from https://developers.google.com/machine-learning/crash-course/descending-into-ml/training-and-loss
Jnagal, A. (n.d.). Image processing with deep learning- A quick start guide. Intelligent Automation. Retrieved April 27, 2022, from https://www.infrrd.ai/blog/image-processing-with-deep-learning-a-quick-start-guide
Kurama, V. (2021, August 19). Machine Learning Image Processing. AI & Machine Learning Blog. Retrieved April 27, 2022, from https://nanonets.com/blog/machine-learning-image-processing/
Lendave, V. (2021, November 17). A tutorial on Sequential Machine Learning. Analytics India Magazine. Retrieved April 27, 2022, from https://analyticsindiamag.com/a-tutorial-on-sequential-machine-learning/
Machine learning basics - youtube. (n.d.). Retrieved April 28, 2022, from https://www.youtube.com/watch?v=ukzFI9rgwfU
Machine learning PPT slides machine learning description designs PDF. SlideGeeks. (n.d.). Retrieved April 27, 2022, from https://www.slidegeeks.com/business/product/machine-learning-ppt-slides-machine-learning-description-designs-pdf
Matuszewski, J., & Rajkowski, A. (2020, February 11). The use of machine learning algorithms for image recognition. SPIE Digital Library. Retrieved April 27, 2022, from https://www.spiedigitallibrary.org/conference-proceedings-of-spie/11442/1144218/The-use-of-machine-learning-algorithms-for-image-recognition/10.1117/12.2565546.full?SSO=1
Mishra, M. (2020, September 2). Convolutional Neural Networks, explained. Medium. Retrieved April 27, 2022, from https://towardsdatascience.com/convolutional-neural-networks-explained-9cc5188c4939#:~:text=A%20Convolutional%20Neural%20Network%2C%20also,binary%20representation%20of%20visual%20data.
Python machine learning tutorial #8 - youtube. (n.d.). Retrieved April 28, 2022, from https://www.youtube.com/watch?v=Zi4i7Q0zrBs
Python machine learning tutorial (data science) - youtube. (n.d.). Retrieved April 28, 2022, from https://www.youtube.com/watch?v=7eh4d6sabA0
Rajat Sharma Follow. (n.d.). Machine learning PPT. SlideShare a Scribd company. Retrieved April 27, 2022, from https://www.slideshare.net/RajatSharma397/machine-learning-ppt-143214180
YouTube. (n.d.). YouTube. Retrieved April 27, 2022, from https://www.youtube.com/index
ABOUT THE AUTHOR

Sayandeep Dey
Sayandeep Dey is an avid machine learning enthusiast who enjoys programming and learning about new concepts and ideas related to coding. He always has an open mind and is very keen on helping the world with his skills in programming. As a passionate programmer since grade 8, he hopes to learn much more about machine learning and big data, and harness that knowledge to help the world in several aspects. Sayan would not only like to see his work come to fruition in the near future, where plastics can be recycled more efficiently, but also implement machine learning practices in various other fields to benefit society.